

Contextes et encodage
Irina semble avoir abandonné le projet, c'est donc seul que je dois terminer le programme et créer le site Internet. Mes connaissances en russe étant limitées, je suis contraint de ne pas traiter le troisième fichier d'URL. Ces URL ne figureront plus dans mes tableaux.
Depuis la dernière fois, j'ai modifié le script de façon à ce qu'iconv ne serve plus qu'à détecter si une page aspirée est en UTF-8 ou en ASCII. En effet, iconv ne fait qu'analyser les octets du fichier pour en déduire l'encodage. Or les différents encodages en 8 bits ne sont pas discernables de cette façon. Il est seulement possible de détecter de façon sûre si des caractères sont écrits en Unicode ou en ASCII.
Ainsi, pour toutes les pages qui ne sont ni en UTF-8 ni en ASCII, le programme va directement chercher un charset dans le code source.
Enfin, grâce à Serge Fleury, notre professeur, j'ai pu résoudre le problème qui empêchait l'affichage dans le tableau du nombre d'occurrences du mot étudié. La sortie de la commande egrep était envoyée à un fichier texte, et non redirigée vers la fonction wc (word count).
Après la création de fichiers texte avec le contexte, j'ai utilisé le programme minigrep multilingue pour récupérer les contextes au format HTML (via l'utilisation de la commande perl).
Enfin, j'ai fait en sorte que le script regroupe tous les contextes dans un gros fichier texte et un gros fichier HTML.

(contextes regroupés dans un gros fichier texte)
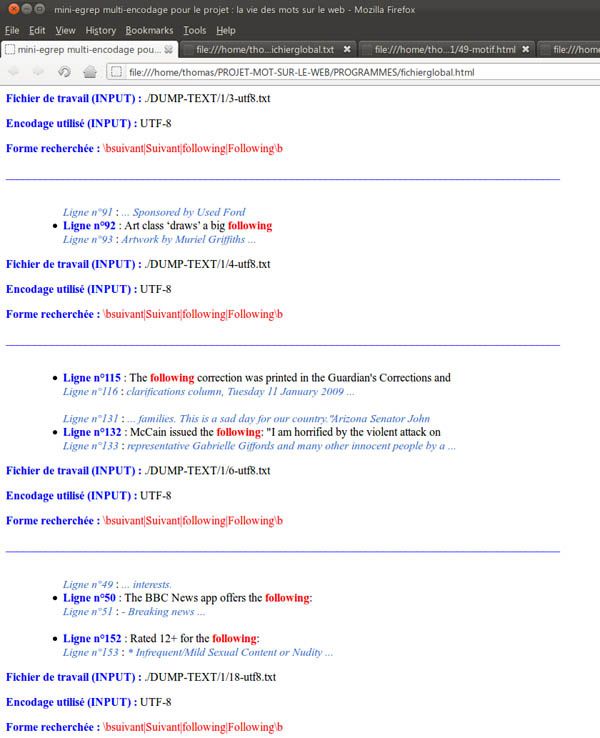
(contextes dans un fichier HTML)
Voici donc un extrait du tableau final :
